A common misunderstanding perpetuated in most grade schools is that science is about “facts”.
Contrary to popular belief, working scientists don’t talk much about facts. They talk about questions, hypotheses, models, and possible experiments. They say things like, “Here’s how you could really demonstrate that” or “Here’s what we found” more often than “These are the facts.”
The public often wants science to settle for us what is true and what is false. But science is really about using theory and evidence to estimate the relative certainty of different claims along a continuous spectrum. Science is really about different levels of uncertainty.
An important outcome of science is to transform a simplistic question like “Does X cause cancer?” into better, clearer questions like “How much does the probability of getting cancer increase with every year spent regularly doing X?” When I started my PhD back in 2009, my question seemed so simple: Do vampire bats prefer to feed those that have previously fed them? I’ve now been working on this question for more than a decade, and although I’ve learned a lot about vampire bat cooperation and the growing evidence is pointing further and further towards yes, I still can’t give a definite answer to that simple question. Instead, I have many more nuanced questions, each of which I need to solve to go further.
My graduate student Bridget Brown just recently published her MSc thesis: Do bats use guano and urine stains to find new roosts? One can guess from the title being a question that we had some hard-to-interpret null results. I think her experience and the story behind this paper is a good illustration of the nuanced relationship between science and uncertainty.
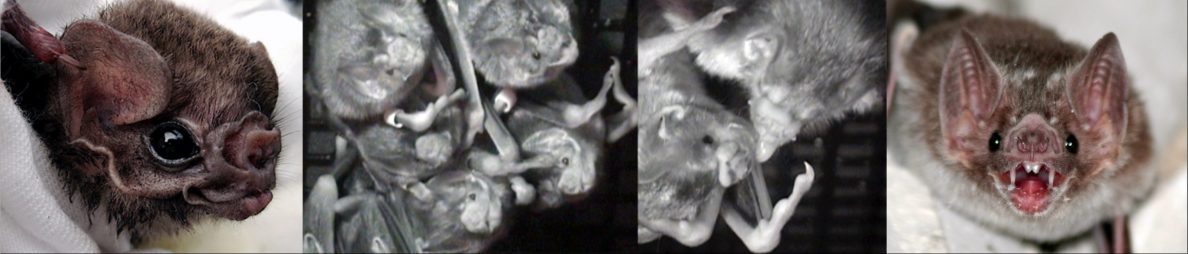
The hypothesis that bats use guano and urine scent to locate roosts was first suggested to me by a bat biologist and bat exclusion expert, who was convinced that bats find entry ways into buildings using olfactory cues from stains of guano and urine that accumulate at entrances to roost crevices, like a small opening to an attic or hollow tree. This behavior would not be too surprising as many mammals scent-mark with urine, and both trained dogs and predators can find bat roosts using scent. In Argentina, I know one vampire bat researcher who is convinced that vampire bats even leave urine trails to their roosts. In the United States, some people stain bat houses with guano and urine to help attract bats, and although some people think this ‘olfactory lure’ works, others seem equally confident that it does not.
When I was working with captive vampire bat colonies during my PhD, my undergraduate assistants and I ran some simple experiments to see if the bats would be more likely to hide in dark places that smelled like guano and urine from their own colony. In most cases, the bats refused to hide in either refuge but when they did choose one, the results were pretty striking. For example, in one test, bats chose to hide in a dark scented refuge over a dark unscented refuge in 9 of 10 trials where they entered one of the refuges. However, when we tried a different version of this experiment in Panama, the results were less clear. Another problem was that the trials were not videotaped, so we could not check the observations.
We submitted the results from these experiments suggesting that lone vampire bats are biased towards roosting in areas with familiar guano and urine scents, but also that this effect was not as strong or immediate as their bias towards calls recorded at familiar roosts. The reviewers had no major issue with the methods, but they thought the conclusion was too obvious and unoriginal. Weirdly, they also asked us to only present the results of only one experiment rather than all the results we collected, which they considered redundant. The manuscript sat on the shelf for a bit.
My MSc student Bridget Brown decided to work on this question and become the newest member of the “feces theses” club, for people in organismal biology who earned a degree working with poop (there are so many of us). She attempted to compile all the previous evidence, replicate the original results with greater rigor, improve the methods, and add two field experiments. I knew the field experiments were risky, but I thought I was giving Bridget a project that also had a pretty safe result: replicating the captive tests. But much to my surprise, the captive results did not replicate.
There are two kinds of null results: an effect size that is unclear and an effect size that is close to zero. Bridget’s MSc thesis had both kinds. The field experiments had completely unclear results. The captive experiments found no bias towards the scents in the two bat species she tested, but we could not say for sure how well these negative results generalized to other contexts.
Many graduate students fear null results, but I think null results are an important and useful experience to have, especially when you first start your career in science, because they teach you several lessons about how science actually works.
First, null results force you to confront uncertainty directly, rather than simply making one claim versus another. Null results teach you about statistical power. In my experience, most students in behavioral ecology think about statistical power, but not enough to explicitly work that into the design of their experiments to know in advance what kinds of effect sizes they can expect to detect. In animal behavior, sample sizes are often determined more by logistical difficulties and access to time and resources than to study design.
Second, students must remember that some of the most important results do not confirm a hypothesis, but rather they actually decrease our confidence in something we thought we knew. Before Bridget’s experiment, I thought vampire bats would almost always prefer to roost in areas with familiar scents, but now I was much less certain.
Third, null results force you to think about how much confidence you have (or should have) in the ‘null hypothesis’. For example, I had a strong a priori belief in what the result would be, but Bridget was more skeptical than me about the use of scent, because she never saw the positive results. From a Bayesian perspective, Bridget and I had different priors. Most biologists use frequentist statistics, but I think everyone should keep a Bayesian perspective in mind, because the confidence for a claim being true or false cannot be based on a p-value.
Perhaps, most importantly, null results show you that science is often just very difficult. The reality is that when you set out to answer a big question as a graduate student, you almost never do. More often, you gather evidence about a smaller question– a significant piece of the much larger puzzle. You often fail to achieve everything you wanted, but hopefully you learn something new, and you always still learn a lot from what you did. I was impressed with Bridget’s creativity, independence, and grit. During the one summer of fieldwork she had, she organized three experiments in two countries. She taught herself how to write R code, and organized a student coding club that met every week. She demonstrated a great work ethic. She completed every task she planned to do during her field season, she overcame every obstacle she encountered, and she also helped everyone else with their projects. Doing all that and having everything go wrong is part of science, and makes you appreciate how wonderful it is when things actually work.
Bridget started with a simplistic question (Do bats use guano scents to find roosts?) and began to think about more nuanced ones. Some answers were clear: Are isolated vampire bats as strongly attracted to familiar guano and urine scents as they are to sounds of calls from familiar roostmates? No. Others remain unclear: Does painting bat houses with guano make bats more likely to come and check them out? Under what conditions is an attraction to roost scent cues present or absent, or stronger or weaker? Does it depend if the bat is in search of new roosts or returning to a familiar one? Does the familiarity of the scent matter? Does the motivational state matter? What about different species? What about the sex of the sender and receiver?
Overall the results corroborated results from European bat species that bats are immediately attracted to acoustic cues but not scent cues. Calls indicate the presence of a conspecific bat here and now, whereas a guano or urine stain is only a cue of a bat being present at some time in the past. Moreover, any chemical cues in guano and urine are also likely to be less salient than chemical signals from clear scent marking signals.
Bridget also did a review of the literature on this topic and again there was more uncertainty. In several studies, different bats used odor, but not necessarily guano or urine stains, to choose a roosting site or to recognize familiar individuals. In one study, male bats clearly appeared to use urine to set up territories. Other results were unclear. Different results could be due to differences between species or between study designs. The quality of evidence was also highly variable. Some studies were not capable of showing an effect in either direction, yet people had cited them as an argument in one direction or another. Other studies were well-designed, but still difficult to generalize from. In two unpublished graduate theses, data were collected but were not (or could not be) properly analyzed. An important part of science education is understanding papers not as ‘facts’ but as arguments with evidence that varies in quality. Even when clear findings exist, it does not mean they will replicate in the future.
I think a failure to replicate an expected result, followed by an interrogation of why or why not, is one of the most important experiences you can have in science, because it instills the gift of doubt. Unlike in science lab classes, there are no known answers in real research, so every finding has to be carefully considered and questioned constantly. One has to think carefully about the uncertainty rather than just tell a clear story from whatever data are available.
The problem of incentivizing certainty during the publication process
When you make a scientific argument, you should really give all the information that would make someone doubt you. That is what makes a scientific argument different than a standard academic argument or just any old argument. You cannot be a good scientist if you have absolute certainty in your arguments, and cannot conceive of how they could be wrong. Yet scientists are people, and people like to make their arguments as strong as possible, even if that means hiding information to make things more certain than they are.
One of the ugly binds we have gotten ourselves into in academia is entangling certainty with publication. It’s obvious why we all like certainty. The more confident we can be in the conclusion, the better the paper. Publications want clear and confident narratives because these are more influential, and nobody wants to read a paper on whether X causes cancer and still not know the answer by the end. Many people use scientific publications as the gold-standard of what to believe. Science is as certain as certain gets.
Yet, I think we still reward certainty too much, and too many papers don’t discuss their limitations (nor is that even expected in many fields). As you develop as a scientist, you start becoming increasingly skeptical about the results of papers, because you start noticing all the flaws and/or interpretations you don’t agree with. As a reader, you become increasingly skeptical of claims made in high-impact papers, even in the most prestigious well-regarded journals like Nature or Science, while noticing really solid work in “lower” journals. As a non-expert reader, you focus on the findings, but as an expert reader you read the methods carefully and often this makes you place a very different level of confidence in the results than you would from reading the text of the results or discussion alone. As a reviewer, you find major flaws in papers that the other reviewer doesn’t notice. At some point, you stop assessing whether a claim in a paper is likely to be true based on the journal reputation or even because it’s in a peer-reviewed journal. At first, this is frustrating, but eventually you realize that the world is just complicated and full of uncertainty.
As an author, you realize over time an equally important lesson: that nature does not owe you anything, and no matter how hard you work, you are not guaranteed a clear result. No one is entitled to an influential, high-impact publication. It’s Murphy’s Law. Even if you do everything right, you can lose a year’s worth of data when your frozen samples are lost in customs, or your field site is destroyed by a fire (one of my friend’s field sites was wiped out by a mining operation, twice). And that’s if you do everything right, which is also unrealistic. Almost nobody does everything right, especially not the first time. In many fields, you have to do multiple experiments just to figure out how to design the experiment you want to do. Doing something new requires trial-and-error learning, failure after failure, sometimes for years. Learning is making so many mistakes early and often enough that you know what not to do the next time. I’ve been doing science for almost 20 years, and I’m still somehow an amateur. I’m still learning how to do it.
So if scientists are not entitled to clear results, what are we entitled to, if anything? I would argue that everyone is entitled to share what they did in a way that is intellectually honest, without being forced to tell a certain narrative or to make something seem more clear than it was. If you spent months or years collecting data, you should share it with others, because that’s the whole reason you collected it. That doesn’t mean it’s transformative, but it’s also not a waste of time. Other people can use that information in their own studies or perhaps include it in a meta-analysis. Even if you never solved the puzzle, you can help contribute to the answer. There are often many others researchers working on a similar, or even the same question, that could benefit from the insights in your data. And perhaps, the answer will emerge one day in the future.
The problem here is that some people think that if they worked really hard or they had really good ideas, then they deserve to have a big impact, which means a clear and confident story. In some form or another, I think this is the cause of most, perhaps all, scientific misconduct. People who engage in scientific misconduct must think the story is the goal, and the data are just getting in the way.
Doing research is a bit like starting a business. About 90% of start-ups fail, but that’s because they have to convince their investors to invest AND their customers to buy. So even if they are very confident and convincing, they still need to make it all work to be profitable. What if the CEO only had to convince the investors and almost nobody looked at the financial data? Well, almost all businesses would claim to be successful all the time, and that’s precisely what happens, which is why we have so many third-party mechanisms in place to assess company performance, regulate assessment, regulate the regulators, and so on. Similarly, when academic scientists receive funding based on their ability to make dramatic and certain claims about what they did (papers) and what they will do (grants), these incentives are capable of destroying the foundation that makes science work. The glue that holds it all together, that maintains high quality, is peer review, but that is a strained system that is too weak for what is intended to do. It’s so important, yet nobody funds it or even incentivizes doing a good job. Instead, the for-profit publishers walk away with millions of dollars for doing nothing except making the paper hard to access. Also, by the time peer review comes, it’s often too late to be constructive. A better structure would be one that evaluated the study right after study design and right before data collection (a process called pre-registration). This procedure would eliminate the most common forms of scientific misconduct, and make the whole system way more efficient.
Another key problem to overcome is that papers serve two conflicting purposes in academia. They are communications to other researchers, but we tend to treat them more as accolades. We think of the publication as the prize at the end of the research project road. Academics are always counting papers as if that is some kind of measure of one’s quality as a researcher. It’s hard to get a job unless you have many good papers, but people also judge you for having too many papers that are not high impact enough. When people find a mistake or problem and retract a paper– which is a great thing to do because it corrects the scientific record– some people are irrationally judgmental that someone had a paper on their CV that they didn’t “deserve”. Viewing papers as merit badges has led to problems that I’ve written about before when I was a graduate student: authors not being transparent, overstating arguments, avoiding rather than soliciting critical feedback, and generally caring more about impact than accuracy.
Over the last few years I am really inspired by seeing so many scientists changing the way we do science — making data and findings easier to share, improving peer-review to be more robust, and encouraging many new practices of open science. Some of these practices are in the videos below.
Open science data management
Peer community in
Pre-prints
Why we need pre-registered reports
Pre-registered reports
Why you should apply open science practices

Me encantó, lo que leí me motiva a ser mejor estudiante de posgrado, gracias!
LikeLike