My former postdoc advisor, Damien Farine, and I have a new paper entitled Permutation tests for hypothesis testing with animal social network data: problems and potential solutions. There is some debate around the topic of using permutation tests for hypothesis-testing with network data, so I’ll write a bit about that here from my own perspective. My thoughts continue to evolve over time, and I think blogposts are a good place to think “out loud” without having to commit your arguments to a publication.
First, some background on networks…
In animal behavior, social networks involve “nodes” (often individual animals) linked by “edges” (often rates of association or interaction). For example, an animal behavior researcher might repeatedly observe and record individually marked animals seen together in groups and then use co-occurrences of individuals to estimate the association rates between all pairs of individuals over some period of time. That set of sampled individuals and their association rates is the “social network.” Some common questions about social networks are whether individuals have preferred relationships, whether there are distinct subgroups (cliques), whether some kinds of individuals are better connected to others. There’s an important difference between making networks to infer social affinity (e.g. for identifying preferred relationships) versus social contact (e.g. for tracking pathogen transmission). Namely, inferring social affinity is more difficult than inferring contact rates because animals might co-occur in space and time for many reasons besides wanting to be near each other. The contacts are important regardless of why they occurred, but for some questions, we might care mainly about the social preferences, and not who happens to be near who.

There are many challenges when testing hypotheses with animal social network data, and different authors have focused on different problems. The most obvious problem is that network data are inherently interdependent, and most statistical tools of inference rely on assumptions about the independence of observations. There are many solutions to this problem, mostly coming from fields outside of animal behavior like the social sciences, but they all assume that the observed networks are accurate representations of the real social world. Social scientists can safely assume that the reported ‘friendship network’ of a group of people is an accurate description of who considers who to be their friend. We animal behaviorists, however, cannot simply ask animals to report their social preferences, so we have an extra step of inferring the links between individuals. Also, we typically don’t have the same quantity and quality of contact data that one can get from studying people. To put it bluntly, the observed association networks we create are often not very accurate reflections of the animals’ real social preferences, or real rates of interaction, or even real rates of association.
One reason for this gap between the observed network and the real social structure is that networks are often based on datasets that are under-sampling the process of interest. As the number of individuals in the study grows, the number of pairs (possible edges) grows exponentially. Any observational sampling method will struggle to keep up. With under-sampled data, pairs of animals that are unconnected in the network could either be an association rate that is truly zero or one that is simply low. If any given edge is not estimated well, this can have profound implications for conclusions. One solution to this problem is using automated methods (like proximity sensors) which takes a complete census of all contacts over a given time period, or using truly massive long-term observational datasets.
However, even with tons of observed animal interactions or associations, there’s still another problem. Observations of interactions or associations of animals in the field are often full of observational biases caused by the researcher’s incomplete sampling method or the animal’s own behavior. Even biologgers such as proximity sensors can introduce some bias because they are not always perfectly identical in their sensitivity. Animal social networks are not simply shaped by social preferences, but also by the constraints of time and space, by how the observations are made, and possibly by interactions between these factors. For instance, networks might be made from observations at bird feeders, and two rival birds that like the same feeder but actually hate each other might seem to prefer each other’s company, just because they are often seen together near the same feeder. They might associate more than all other pairs, but after controlling for their use of space, we might see that actually associate less than expected from random movement.
Or imagine that in a multiple-year study, two random animals without any special affiliation both die in the first year. These two individuals might seem to have very high association rates simply because they co-existed at the same time. When visualized as a network, these two animals might seem to have a special relationship, but this is yet another sampling bias. Individuals, or categories of individuals, might seem to be “more social” simply due to differences in attraction to observed resources, home range size, or mortality in different habitats. Individuals might seem to prefer interacting with kin simply because kin are born closer in space.
Imagine a scenario where male and female cardinals are equally social, but males are more likely to be observed socially interacting because they have brighter red plumage and are thus more likely to be seen by the researchers. The researchers might incorrectly conclude that males are more social than female. Sampling bias strikes again.
Here’s one more example: imagine that all individual pigeons in New York City have the same number of frequent associates, and the researchers attempt to measure this by collecting observations of flocks in Central Park. Those pigeons living near the center of Central Park will tend to have associates that are also at Central Park, whereas individuals living at the edge of Central Park will tend to have associates living outside the park that are therefore never observed by the researchers. The researchers might then incorrectly conclude that pigeons living near the center of Central Park have more associates and are more social. In this case, sampling bias is caused by the limits on the area that can be studied.
In summary, social networks (and the measures we take from them) are shaped not only by social traits such as “gregariousness” or “social relationships”, but also by “nuisance effects” such as sampling biases or attraction to shared resources.
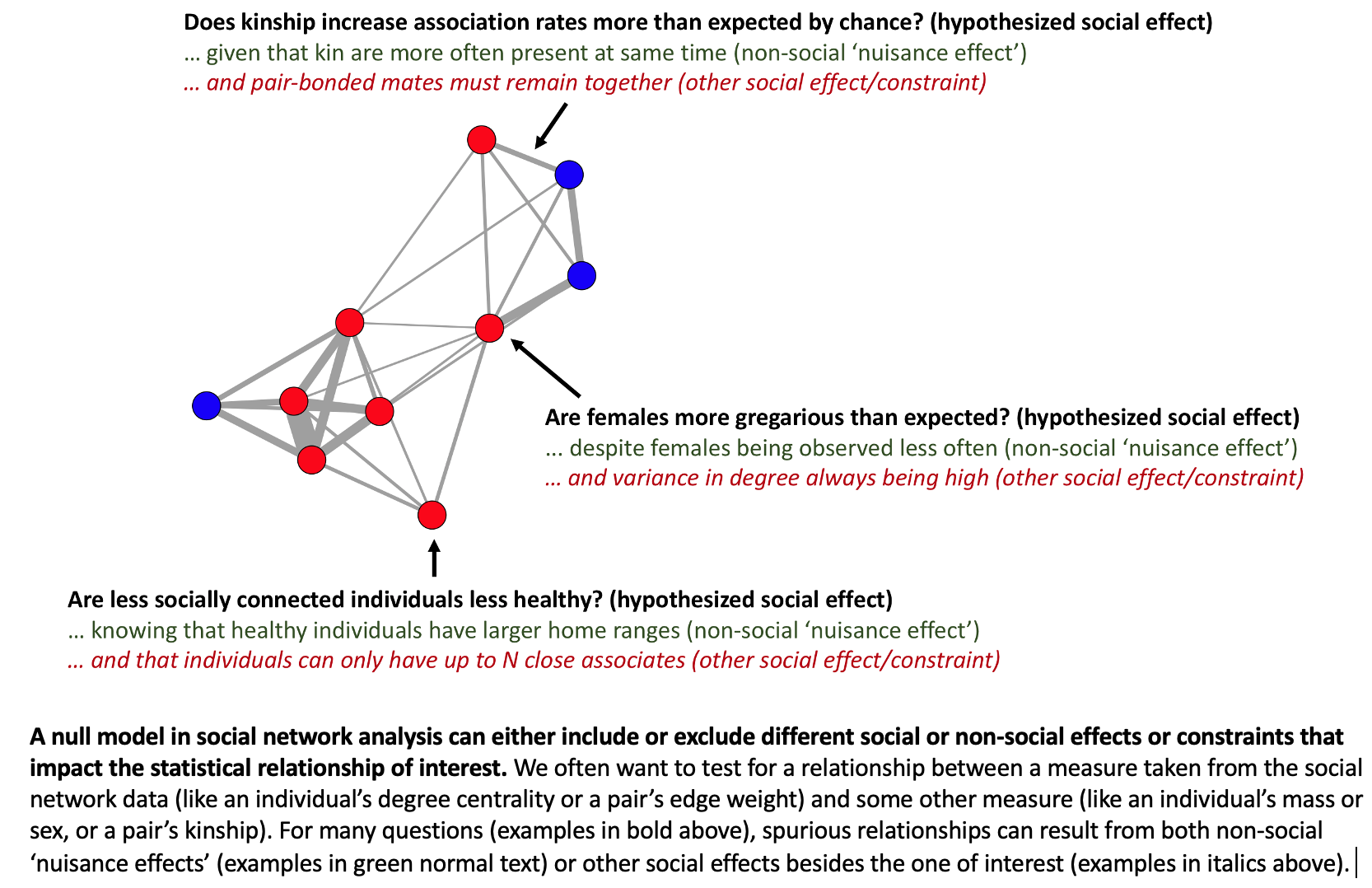
By teaching workshops on animal social network analysis, Damien came to the opinion that (1) such biases were very common in the datasets from field studies, (2) the researchers were often unaware of such problems in their data, and (3) there was a frequent naïve assumption that the researcher’s observed social network was an accurate map of the animal’s preferences for each other.
Not everyone agrees on how big a of a problem this is. One could also point out that the reliability of the data is not part of social network analysis. It’s simply the researcher’s job to ensure that the network is accurate, which means that there is enough data to precisely estimate every network edge.
One might also ask, “But aren’t these sampling biases, spurious correlations, and nuisance effects common in every kind of statistical analysis we do in biology?” Yes, but their effects on social network data are so much worse because a bias in say 1 individual out of 100 influences that individual’s association rates with all 99 other individuals. In normal statistics, errors are independent, but in social network analysis, they can affect every other observation as well.
Note that these biases are “baked into” the network. Once the network is created, you can no longer control for them or even “see” them in the network data. If two individuals are highly associated or never associated, it won’t be clear why from the network itself. For example, an association rate of 100% or 0% could be based on 500 observations or just five. That is, the precision of each edge is typically not “visible” in the network data because, when using typical approaches, an edge weight is a summary statistic like the mean or sum of contacts.
So what do we do? One approach is to control for many of these biases by using a null model that takes them into account. By permuting the observations before creating the network, one can simulate what the data would look like if the animals acted randomly, while controlling for the effects of individual, time, and space. To do this, one swaps observations of the same individual within the same location or period of time. These data permutation methods were developed by Bejder et al. in 1998 and were used and promoted by researchers like Hal Whitehead and Damien Farine. To make them accessible without writing the code from scratch, Hal Whitehead developed the Matlab-based program SOCPROG, and Damien wrote the R package asnipe. These permutations, which are conducted on the observation data rather than the network, are typically called “datastream permutations” or “pre-network permutations” to distinguish them from permutations of the network (summary) data, e.g. “node-label permutations”.
In 2020, a team of researchers who specialize in social network analysis (Michael Weiss, Dan Franks, Lauren Brent, Sam Ellis, Matt Silk, and Darren Croft) wrote a paper entitled “Common datastream permutations of animal social network data are not appropriate for hypothesis testing using regression models.” In this paper, they showed that while pre-network permutations were fine for testing the null hypothesis of random social interactions (as they were originally intended), they should never be used to test the relationship between a predictor and a response such as: “Does kinship predict association rates?” or “Does sex predict network centrality?”. When used to test the statistical significance of a linear model (the “effect” of X on Y), pre-network permutation tests have very high rates of false positives. The same basic problem was reported in another paper by Ivan Puga-Gonzalez, Cédric Sueur, and Sebastian Sosa entitled “Null models for animal social network analysis and data collected via focal sampling: Pre-network or node network permutation?”
The null model from pre-network permutations can answer the following question: “Is this observed relationship between X and Y different than what is expected from the animals acting randomly with respect to each other (i.e. random social network structure)?”
But in many cases what the biologist actually wants to know is: “Is this observed relationship between X and Y different than zero given that the animals have a (typically nonrandom) social network structure?”
The traditional permutation approach to answer this question is to create a null model by permuting the nodes within the network while keeping the network structure the same, the so-called “node-label permutation test”. A mantel test is one example. Another is MRQAP (multiple regression quadratic assignment procedure) which allows for network regression with one or more predictor networks. The problem though is that if we use a node-label permutation test, we are back to assuming that the estimated association rates are a reliable estimate of the true association rates (or depending on the hypothesis, we might be assuming that it reflects the true social affinities). These might be a valid assumption, but for many if not most animal datasets, they are not.
Damien and I decided to see if we could “fix” this problem. Although pre-network permutations could easily be used to test the wrong null model, they were also a useful way to eliminate all these nuisance effects that made the observed network an unreliable representation of the real network. We tried to first use pre-network permutations to adjust the observations of individuals or interaction rates relative to what they would have been by chance and then use node-label permutations to test the significance of the effect? Would this eliminate the high error rates while also controlling for the biases? Indeed, it did.
Damien and I hoped that, until someone more clever than us could develop a better solution, we should still present a working permutation approach to dealing with nuisance effect when testing hypotheses using social network data.
We sent the other team our manuscript for feedback. We realized we initially had some very different views on how to best do hypothesis testing with animal social networks. Note that this difference of perspectives and the subsequent convergence of ideas is how and why science works!
The counter-argument against the use of permutation tests, made most consistently by Dan Franks, is that researchers need to move this entire subfield of animal social network analysis away from permutation tests, because they only give you a null model and a p-value. With permutation tests the researcher controls for all of the “nuisance effects” within the null model, rather than attempting to estimate each of them within the statistical model (as random effects or covariates). Putting all the hypothesized effects into the statistical model (not the null model) is how we normally do statistical inference. To control for the effect of the actor, you add actor as random effect. To control for the effect of time, fit time as a covariate (or a random intercept or slope to look at effects within day). Fitting a model this way gives you effect sizes (and the ability to estimate their precision), rather than just a test of a null hypothesis by comparison of a null model. Even more important, model-fitting allows researchers to incorporate more orthodox and modern statistical approaches, including Bayesian inference. As we all know, p-values by themselves have extremely limited value as a tool to assess evidence for a claim. Indeed, some biologists would say we should not be testing null hypotheses at all, but instead fitting a model to the data, estimating effect sizes, and putting a probability distribution around it (using Bayesian inference). But most biologists still use p-values. Let’s sidestep the frequentist vs Bayesian debate for now. For Dan Franks and others, the fact that permutation tests pushed researchers away from model-fitting, and thereby away from effect sizes and measures of their uncertainty, was a nail in the coffin for using permutations tests for hypotheses about social networks.
On the other hand, it’s not immediately clear to many of us how to accomplish what pre-network permutations can do so easily (controlling many interacting nuisance effects at once) within a statistical model with network data. For starters, the model would have to be pretty complex with many terms and fit using the original observation data (the events) not simply the aggregated network data (the edge weights). Perhaps this is being developed right now, or perhaps it already exists. But regardless, few researchers will have the statistical training to deal with the (potentially many) nested drivers underlying the observed data. So depending on your point of view, the paper by Damien and I could be seen as either (1) plugging a hole in a sinking ship of permutation tests or (2) providing the only real practical solution to this particular problem. Or maybe it’s both.
In my opinion, using a permutation test rather than fitting the best possible model is a bit analogous to using a rank transformation to create a nonparametric test (like a Spearman’s correlation, Wilcoxon rank test, or Mann-Whitney U test) rather than fitting a more sophisticated model to data with say a very zero-inflated, very highly skewed, and very non-normal error distribution. Some will say ranking the data is a lame hack and completely outdated. But for the purposes of simply testing a null hypothesis (a difference or correlation), it can get the job done, and for the statistically unsavvy biologist, it is easier to understand and use correctly than fitting more complex models (e.g. a zero-inflated negative binomial model). But this might just be a case of perspective. To other people, it is the permutation tests that are more difficult to understand and implement. So maybe this difference in which approach is more intuitive to each of us comes down to differences in each of our backgrounds or our ways of thinking.
Up until recently, permutation tests were assumed to be necessary by most people in animal behavior because of a lack of interdependence of the data. However, Jordan Hart, Michel Weiss, Lauren Brent, and Dan Franks wrote another paper (still a preprint) arguing that node-label permutation tests do not really resolve the issue of interdependence of observations. They do not control for effects of actor, receiver, or network structure in ways that a mixed effect model or some other model can’t. So from their point of view, perhaps there’s really no good reason to use either pre-network or network permutation tests for testing linear-model-type hypotheses at all. Note that this could not be farther than the approach taken by Damien and I, where our solution was a permutation test inside another permutation test!
I am mostly convinced of the basic argument by Hart et al. that we should eventually move more towards better model-fitting with network data. Permutation-based null models have clear limitations because they are used to test null hypotheses, rather than to generate models of what we think is actually going on. However, the Hart et al. paper again doesn’t discuss the issue of nuisance effects at the level of the observation data distorting the observed social networks, which Damien and I think is a major problem. This is not a fault, flaw, or oversight in the Hart et al. paper, because it also makes sense to ignore this issue here and view the reliability of the network as a completely different problem than analyzing the network itself. Models for analyzing network data can assume the networks are reliable, just as fitting any other statistical model assumes that those data are reliable.
In our paper, Damien and I focused mostly on this issue of messy data leading to unreliable networks or networks that convey association but not social structure. We used pre-network permutations to adjust the values for each node or edge to control for nuisance effects before conducting a node-label permutation test. We called this a “double permutation test”. Dan Franks pointed out that the second permutation test could be replaced with a well-fit parametric linear model (which we agree with), but we kept the ‘double permutation’ name. I think Damien and I both have the intuition that if you want to calculate a p-value you might as well as permutation to do it.
My opinion is that permutation tests are still a very useful tool for the biologist hoping to test a null hypothesis using a custom null model (or using multiple reference models). Whenever you want to see what patterns you should expect from a random process like random choices by animals within some set of constraints, permutation-based null models and similar methods such as agent-based simulations can be very helpful. A recent paper by Liz Hobson et al. entitled “A guide to choosing and implementing reference models for social network analysis” also covers the topic of different ways to make expected reference models for social networks in great detail.
Despite all their many dangerous limitations, I also think there are important uses for p-values (at least until we all switch to a norm of using Bayesian inference). However, it’s not Bayesian inference that will solve the problem described above, rather we all need to become experts at modelling the process of data collection rather than the summary network.
In response to these papers and discussions about frequentist vs Bayesian inference, I finally began reading a number of Bayesian books I had acquired on my shelf. Dan Franks especially recommended “Statistical Rethinking” by Richard McElreath. This book is really a whole course on Bayesian inference and it is accompanied by an R package and the all the course lectures are available on youtube. It’s really good. So I’ve decided I’m learning Bayesian inference. Given how busy I am, this process might take me a few years.
Let’s come back to testing hypotheses with social networks and what methods are best.
Say I’m a graduate student and I collected observations of animals in groups and I want to know whether males and females differ in their gregariousness. What do I do? And why is everyone telling me to do different things? Should I use a permutation test (if so, what kind?), or should I just do a normal parametric model and draw an inference from that?
I would say it depends on how biased and reliable your observations are, and perhaps just as importantly– how comfortable you feel using and understanding the different methods. If you are considering different methods, you can always do them both to see whether you get the same answer. Just be sure not to pick the method based on getting the answer you like!
To conclude…
There are many people working on hypothesis-testing in animal social networks, and authors are often focused on different kinds of problems. As an example from people that I know, Damien has focused largely on the problems created by biases in the observed networks in observational field studies. The team led by Lauren Brent and Dan Franks has been showing the limitations and problems created by permutation tests, and the benefits of fitting a parametric model like a mixed effect model. Another set of authors including Liz Hobson and Noa Pinter-Wollman recently wrote a review on the diverse menu of options for creating reference models using resampling and simulation methods. And that’s before we even get to exponential random graph models, latent space models, stochastic-oriented actor models, and relational event models.
Given all the options, how can we know what methods are practical and work best given different scenarios? We already know a lot of what works with completely reliable networks because that’s what social scientists work with, so to me the question is what to do with messy field observations from animals.
I think we should do a blind anonymous demonstration where many people analyze the same social behavior dataset(s), in which the effects (both the nuisance effects and the effects of interest) are unknown to the participants doing the analyses (but known to someone else in advance). The outcome would be a series of analyses (e.g. R scripts) showing how different people test a hypothesis with social network data, and what kinds of results we get with different approaches.
We need this because the current situation is that different authors explain (or advocate for) their methods using simulations with datasets they generated, but then we don’t see side-by-side how various methods differ from what someone else would have done with the same data. If the same dataset was analyzed in multiple ways by multiple people that are blind to the true effects, this experiment would tell us what methods worked well under real-world conditions.
An example of a similar study comparing two methods for hypothesis-testing was done by Evans et al (2020) and entitled “The performance of permutations and exponential random graph models when analyzing animal networks”.
Such an exercise would give us some useful insights. We wouldn’t need to discuss who did the analysis well or not; that’s not the point. It would just be inherently interesting to see what mistakes were made, what approaches gave insights that were not available from other approaches, and what approaches were more flexible or not, complex vs simple, easy vs difficult (all while keeping anonymity of participants). Perhaps some methods work best with different kinds of data. Perhaps some methods are more conservative overall. Perhaps some methods are more powerful but also easier to mis-use?
And, maybe most importantly, such a process would produce detailed hands-on guides for other researchers, as people could see the code underlying the analysis process itself.
There are many details to work out how this would happen, but I think this is a good idea, and I hope it happens…. But I’m not doing it. I’ve already used up the tiny slivers of free time I have writing this blogpost.
——–
Please feel free to email me with your thoughts on this topic or write comments below.
Thanks to Damien Farine for his support and always giving me constructive feedback on this topic, and also thanks to Jordan Hart, Lauren Brent, Dan Franks for taking time to meet with me to discuss their work.
Final thought: For some reason, I always find myself drawn to scientific disagreements, longstanding controversies, and highly debated topics (like the evolution of cooperation). Sometimes I’m shocked by how tribalistic and extreme these debates can get. The big dramatic disagreements really stick out. My favorite example is the Harvard evolutionary theorist Martin Nowak citing on his lab web page that “Our ambitious goals include curing the world of cancer, infectious disease, and inclusive fitness theory.”
Yet compared to other kinds of debates, I’m often impressed by the kindness and civility of scientists even when they really disagree. I see so much alienation and frustration on social media these days rooted in ethics, epistemology, and politics. The way we most often deal with this is just avoiding people with whom we disagree. In contrast, science has always been a solace for me where I feel I can have constructive, friendly, and reasonable discussions with people with different views that change how I think. Scientists have the same human foibles as everyone, but we continuously try to build norms and systems (however imperfect) to try and work against our biases. As human beings, we of course think our own intuitions, ideas, and perspectives are best. But as scientists, we also try to converge; we agree in advance about what new experiments, information, or discoveries would help change our mind, and this forces us to imagine how we could be wrong, or how a different view could be valuable. Rather than splintering into new fields every time there is disagreement, scientists have a norm of using reason and evidence to converge on shared reality. I think there’s an often under-appreciated lesson there for other intellectual domains.

{kind=link}
One thought on “New paper on analyzing animal social networks”